|
Panwang Pan | 潘攀望
Hi, I’m Panwang Pan, a Senior Researcher at ByteDance working at the intersection of generative AI and multimodal learning.
At ByteDance, I turn research into large-scale, production-ready systems built on generative and multimodal models—work that is ongoing.
 Email
/
Email
/
 Google Scholar
/
Google Scholar
/
 GitHub
/
GitHub
/
 Twitter
/
Twitter
/
 WeChat
WeChat
|

|
 ByteDance — Beijing, China - Full-time Employee. ByteDance — Beijing, China - Full-time Employee.
|
09/2022 - Present |
 Alibaba Cloud — Hangzhou, China - Full-time Employee. Alibaba Cloud — Hangzhou, China - Full-time Employee.
|
07/2019 - 07/2022 |
 NVIDIA Developer Technology — Beijing, China — Intern. NVIDIA Developer Technology — Beijing, China — Intern.
|
07/2018 - 10/2018 |
📢 News
[2026-02] Five papers accepted to CVPR 2026; one paper accepted to ICLR 2026.
[2025-09] Six papers accepted to NeurIPS 2025, including one oral presentation.
[2025-06] Released PartCrafter, a structured mesh-generation transformer that synthesizes objects part by part.

[2025-01] Three papers accepted to ICLR 2025, including one Spotlight.
|
|
Research Overview
My recent work spans two themes: multimodal generation and multimodal understanding / agents. On the generation side, I emphasize world models (scene generation) and video generation. On the understanding side, I focus on Jarvis-style systems, agentic workflows, and multimodal reasoning for perception and decision-making.
|
1. Multimodal Generation
World models are central; papers below are ordered as video generation, then world models (scene generation).
Representative topics: dynamic scenes/worlds and controllable video generation.
|
2. VLM Multimodal Understanding / Agent
Jarvis series and related agent systems where VLMs interpret instructions, coordinate tools, and improve downstream perception.
Representative topics: photo retouching agents, multimodal planning, and perception-oriented VLM pipelines.
|
|
|
Multimodal Generation
|
Video Generation
Controllable video synthesis via compositional objectives and language-grounded reward signals.
|
|
Scene Generation and World Models
Dynamic scene generation and modeling (world models), plus motion-aware representations for controllable environments.
|
|
|
DynamicVerse: Physically-Aware Multimodal Modeling for Dynamic Scene Worlds
Kairun Wen, Yuzhi Huang, Runyu Chen, Hui Zheng, Yunlong Lin, Panwang Pan, Chenxin Li, Wenyan Cong, Jian Zhang, Junbin Lu, Chenguo Lin, Dilin Wang, Zhicheng Yan, Hongyu Xu, Justin Theiss, Yue Huang, Xinghao Ding, Rakesh Ranjan, Zhiwen Fan
[Paper]
[Project]
[Code]

DynamicVerse is a physically grounded, multimodal framework for modeling dynamic scenes from real-world video.
|
Multimodal Understanding / Agent
|
This section covers Jarvis-style systems, agentic workflows, and multimodal understanding modules in which VLMs interpret instructions, coordinate tools, and improve downstream perception and decision-making.
|
NeurIPS 2025
|
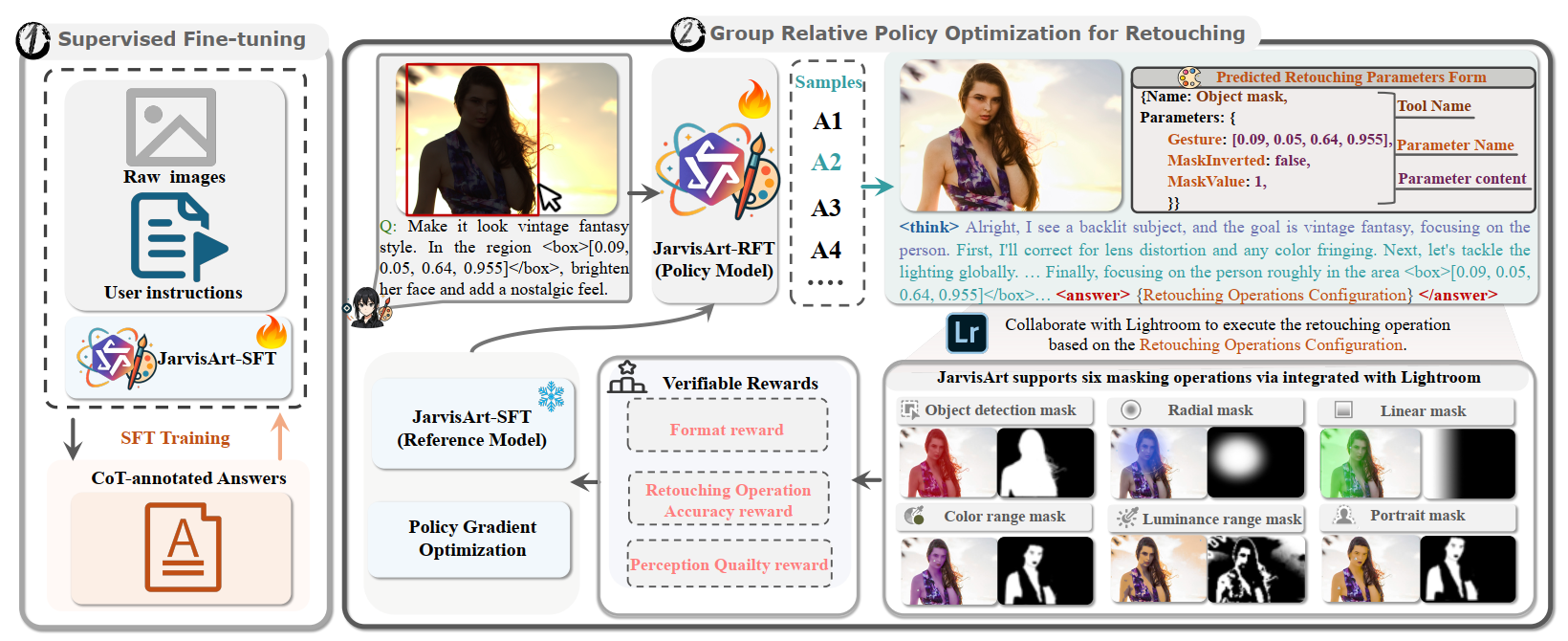
JarvisArt: Liberating Human Artistic Creativity via an Intelligent Photo Retouching Agent
Yunlong Lin, Zixu Lin, Kunjie Lin, Jinbin Bai, Panwang Pan, Chenxin Li, Haoyu Chen, Zhongdao Wang, Xinghao Ding‡, Wenbo Li, Shuicheng Yan‡

JarvisArt demonstrates how an agentic VLM can plan and execute photo retouching while preserving content fidelity and following complex instructions.
|
💬 Miscellaneous
Conference reviewing: NeurIPS, ICLR, CVPR, ICML, ICCV, ACM MM
|
Co-created with OpenClaw and Codex.
|



